Why doing it?
Perhaps, your project has a database-first approach. So, you need an instance of your database for debugging and testing of code.
Nowadays teams can be spread over different regions, having no ability to share a single database instance (which would also be a bad practice because of dependency introduction and drift acceleration).
If your production database is not much evolving in its schema and has a moderate size, such database is a good candidate to be handled as an artefact.
Database artefacts are just right for:
- Reproducing of bugs by deploying a certain version of a database.
- Testing migrations by redeploying a version multiple times.
The good case for making an artefact from a production database is when its schema is managed by some centralized software (not one that’s going to be developed) and you have to just adapt to database changes.
What do you need to minimise burden?
To alleviate burdens you need:
You can use SQL Server Data Tools (SSDT) (requires Visual Studio) instead of SqlPackage for manual extraction of a database schema.
Avoid ‘DOMAIN\User’ format for usernames
The thing that can surprise a developer during deployment of a database in his / her local environment is SqlPackage error like:
Error SQL72014: .Net SqlClient Data Provider: Msg 15401, Level 16, State 1, Line 1 Windows NT user or group 'DOMAIN\ReportJobs' not found. Check the name again.The command CREATE USER [DOMAIN\...] WITHOUT LOGIN; somewhy (even on Linux version of SQL Server) expects Windows NT user or group…
So, don’t hesitate to fix a production database with commands like:
ALTER USER [DOMAIN\ReportJobs] WITH NAME = [ReportJobs]Create feed, PAT and authorize
Database artefact is going to be universal package. You need a feed in your project (create it in Azure DevOps Artifacts).
You need to create your Azure DevOps Personal Access Token (PAT) for accessing the feed. Scope Packaging (Read & write) would be enough. Copy the token value from DevOps, then paste it into CLI command:
vsts login --token tokenHow to create an artefact from a production database?
Prepare
A local folder named artifacts/artifact-name/ in the root of your project is going to be used, so artifacts/ should be in .gitignore.
Scripts
./tools/make-db-artifact.ps1
The tool extracts schema of the database and exports data of some tables from a production database to the files in artifacts/artifact-name/.
Replace artifact-name, server-address, database-name and table names with actual values:
param ( [Parameter(Mandatory=$true)] [String] $login,
[Parameter(Mandatory=$true)] [ValidateNotNullOrEmpty()] [SecureString] $password)
$ErrorActionPreference = "Stop"
# convert a secure password to plain text$BSTR = [System.Runtime.InteropServices.Marshal]::SecureStringToBSTR($password)$unsecurePassword = [System.Runtime.InteropServices.Marshal]::PtrToStringAuto($BSTR)
## PREPARE DIRECTORY#
$path = "./artifacts/artifact-name"
if (!(Test-Path -Path $path)) { mkdir $path}else { Remove-Item $path\*}
## EXTRACT SCHEMA#
SqlPackage ` /a:Extract ` /ssn:"server-address" ` /sdn:"database-name" ` /su:"$login" ` /sp:"$unsecurePassword" ` /tf:"$path/database-name-schema.dacpac" ` /p:ExtractApplicationScopedObjectsOnly=true ` /p:ExtractReferencedServerScopedElements=false ` /p:IgnoreUserLoginMappings=true ` /p:ExtractAllTableData=false
## EXPORT DATA#
function BulkCopy([string]$tableName){ bcp [database-name].[dbo].[$tableName] out $path/$tableName.bcp -N -S server-address -U $login -P $unsecurePassword}
# tables (include only the ones you need)BulkCopy table-nameBulkCopy table-nameBulkCopy table-nameBulkCopy table-nameBulkCopy table-nameBulkCopy table-name..../tools/publish-db-artifact.ps1
Replace org-name, feed-name, artifact-name with actual values:
param ( [Parameter(Mandatory=$true, ValueFromRemainingArguments=$true)] [ValidatePattern('^\d{1}.\d{1}.\d{1,5}$')] [String] $version)
vsts package universal publish -i https://dev.azure.com/org-name/ --feed feed-name --name artifact-name --version $version --path ./artifacts/artifact-nameExecute “make” then “publish” tools provided above.
Manual approach
An extraction can also be done with SQL Server Data Tools:
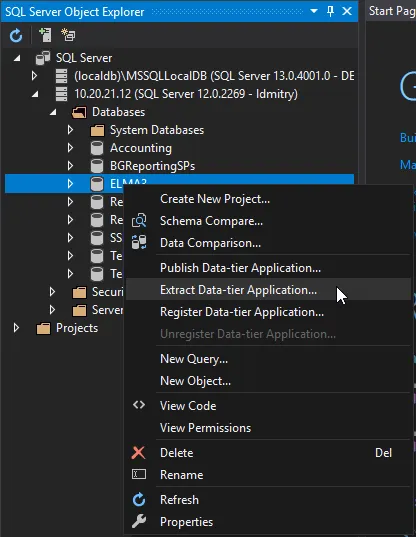
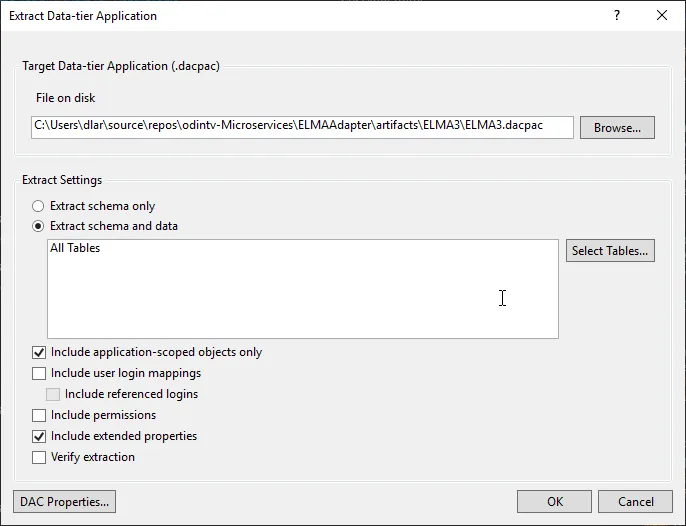
I recommend to extract “schema only” and use bcp tool for tables. If you opt to “schema and data” having a foreign keys in your database, probably, you have no choice except to export all the data, which can be of a huge amount.
You can upload a package version with the command:
vsts package universal publish -i https://dev.azure.com/org-name/ --feed feed-name --name artifact-name --version version --path ./artifacts/artifact-nameHow to deploy a database in a development environment?
Scripts
docker-compose.yml
I hope your development environment is started with docker-compose, so there are some docker-compose.yml where you put an arbitrary sa password:
version: "3"services: sqlserver: image: mcr.microsoft.com/mssql/server:2017-latest-ubuntu container_name: db ports: - 11433:1433 environment: ACCEPT_EULA: 'Y' SA_PASSWORD: 'SomeArbitraryPassw0rd'In this example I map dockerized SQL Server to the port 11433.
./tools/get-db-artifact.ps1
To get an artefact to ./artifacts/artifact-name/ back from Azure DevOps Artifacts use a script like:
param ( [Parameter(Mandatory=$true, ValueFromRemainingArguments=$true)] [ValidatePattern('^\d{1}.\d{1}.\d{1,5}$')] [String] $version)
$ErrorActionPreference = "Stop"
vsts package universal download -i https://dev.azure.com/org-name/ --feed feed-name --name artifact-name --version $version --path ./artifacts/artifact-name./tools/deploy-db-artifact.ps1
The sa password (from docker-compose) I use in the deployment script, that looks like:
$password = "SomeArbitraryPassw0rd"
$ErrorActionPreference = "Stop"
$path = "./artifacts/artifact-name"
## PREPARE DATABASE#
sqlcmd -S tcp:localhost,11433 -U sa -P $password -i $PSScriptRoot/sql/db-artifact-pre-deploy.sql
## PUBLISH SCHEMA#
SqlPackage /a:Publish /tcs:"Server=tcp:localhost,11433;Database=database-name;User Id=sa;Password=$password;" /sf:"$path/database-name-schema.dacpac"
## IMPORT DATA#
function BulkCopy([string]$tableName){ bcp dbo.$tableName in $path/$tableName.bcp -N -S tcp:localhost,11433 -d ELMA3 -U sa -P $password -q}
# tablesBulkCopy table-nameBulkCopy table-nameBulkCopy table-nameBulkCopy table-nameBulkCopy table-nameBulkCopy table-name...
## POST-DEPLOY#
sqlcmd -S tcp:localhost,11433 -U sa -P $password -i $PSScriptRoot/sql/db-artifact-post-deploy.sqlI have added some ./tools/sql/db-artifact-pre-deploy.sql and ./tools/sql/db-artifact-post-deploy.sql scripts to the example, which usually are needed to:
- Check if the database exists, drop and recreate it (pre-deploy).
- Create a login and a corresponding user for software you develop.
- Update sequences and other things corresponding to the table data.
Rollout step-by-step
On a developer’s machine there should be, again: Docker, VSTS CLI, sqlcmd, bcp and SqlPackage.
He or she ought to be authorized to Azure DevOps:
vsts login --token tokenTo get an environment up he / she need to:
Start containers:
docker-compose upGet an artefact:
./tools/get-db-artifact.ps1Deploy an artefact:
./tools/deploy-db-artifact.ps1